Distributed SQL on AWS: Understanding Aurora DSQL Internals
Amazon’s Aurora DSQL represents a major shift in how we think about distributed SQL databases on AWS. This new serverless distributed database service removes the complexity of managing database infrastructure while delivering the consistency and performance that modern applications demand.
This deep dive is designed for database engineers, cloud architects, and development teams who need to understand how Aurora DSQL works under the hood and how to get the most out of it in production environments.
We’ll break down Aurora DSQL architecture and explore its core components that enable seamless scaling across multiple regions. You’ll learn about the sophisticated mechanisms Aurora DSQL uses to maintain data consistency while distributing workloads efficiently across AWS infrastructure. We’ll also cover proven performance optimization strategies that help you fine-tune DSQL workload optimization for your specific use cases, plus practical migration pathways from traditional database setups to this distributed SQL AWS solution.
Understanding Aurora DSQL Architecture and Core Components
Multi-master distributed database engine fundamentals
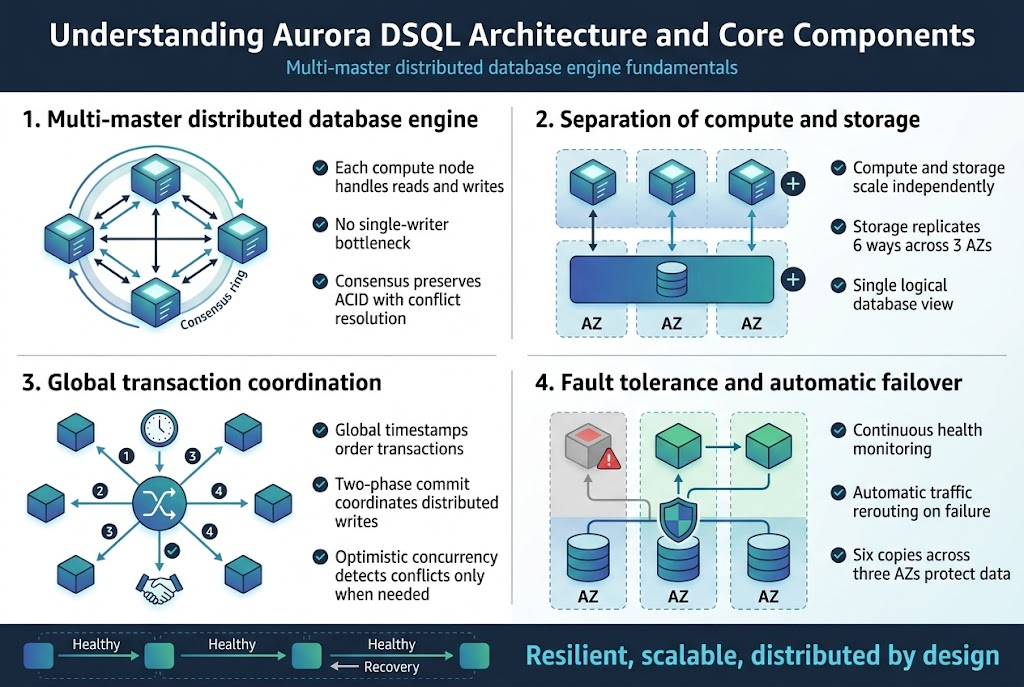
Aurora DSQL’s architecture centers on a revolutionary multi-master approach that breaks away from traditional single-writer limitations. Each compute node can process both read and write operations simultaneously, creating a truly distributed system where data modifications happen across multiple nodes without bottlenecks. This design eliminates the primary-replica hierarchy that often creates performance constraints in conventional databases.
The engine coordinates writes through sophisticated consensus algorithms that maintain ACID properties while allowing parallel processing. When conflicts arise between concurrent transactions, the system uses timestamp ordering and conflict resolution protocols to ensure data integrity across all nodes in the Aurora DSQL cluster.
Separation of compute and storage layers for scalability
The decoupled architecture separates processing power from data persistence, allowing each layer to scale independently based on workload demands. Compute nodes handle query execution and transaction processing, while the storage layer manages data durability and replication across multiple AWS Availability Zones. This separation means you can add more processing capacity without touching storage, or expand storage without affecting compute resources.
Storage automatically replicates data six ways across three availability zones, creating a self-healing distributed storage system. When compute nodes need data, they access it through a high-speed network that abstracts the underlying storage complexity, making the entire system appear as a single logical database.
Global transaction coordination mechanisms
Amazon Aurora DSQL implements a sophisticated transaction coordinator that manages distributed transactions across multiple nodes and regions. The system uses a combination of two-phase commit protocols and distributed timestamps to ensure consistency without sacrificing performance. Each transaction receives a global timestamp that helps order operations across the distributed environment.
The coordinator tracks transaction dependencies and manages commit ordering to prevent conflicts. When transactions span multiple nodes, the system uses optimistic concurrency control combined with conflict detection mechanisms that allow most transactions to complete without coordination overhead, only intervening when actual conflicts occur.
Built-in fault tolerance and automatic failover capabilities
Aurora DSQL’s fault tolerance goes beyond simple replication by implementing continuous health monitoring and proactive failure detection. The system constantly checks node health, network connectivity, and storage integrity, automatically routing traffic away from problematic components before failures impact applications. When a compute node fails, traffic instantly shifts to healthy nodes without manual intervention.
The storage layer maintains six copies of data across three availability zones, allowing the system to tolerate the loss of an entire zone plus one additional copy without data loss. Recovery happens automatically through background processes that restore redundancy levels, while applications continue running without interruption through the remaining healthy infrastructure.
Key Benefits of Aurora DSQL for Modern Applications
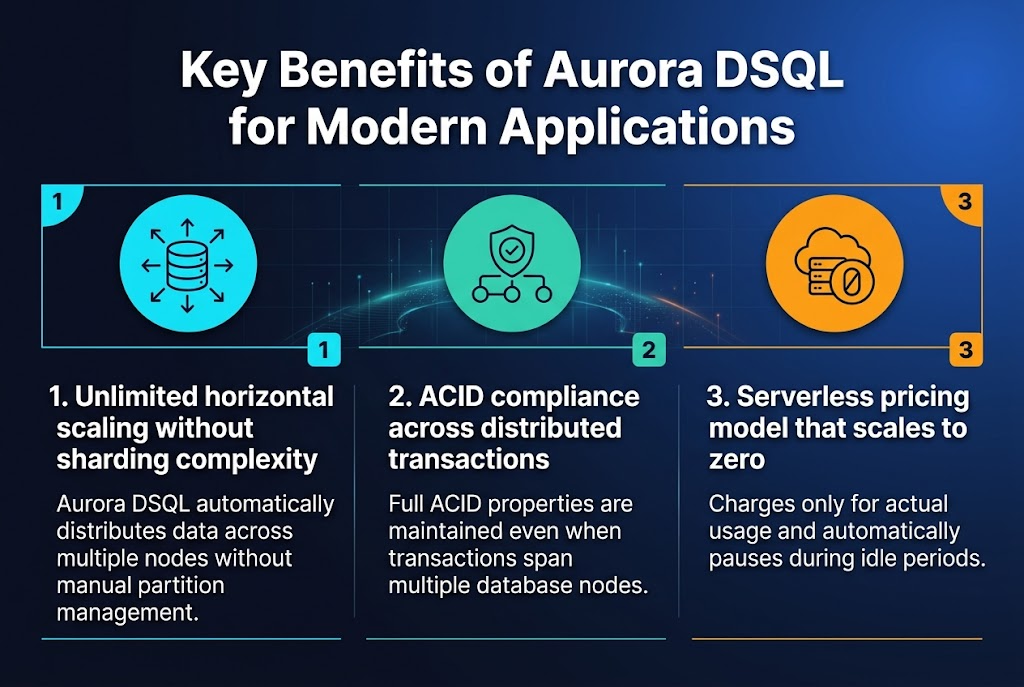
Unlimited horizontal scaling without sharding complexity
Aurora DSQL eliminates traditional sharding headaches by automatically distributing data across multiple nodes without requiring manual partition management. Developers can focus on building applications while the distributed SQL database handles scaling operations seamlessly behind the scenes.
ACID compliance across distributed transactions
The distributed SQL AWS service maintains full ACID properties even when transactions span multiple database nodes. Aurora DSQL architecture ensures data consistency through sophisticated consensus protocols, making it reliable for mission-critical applications that demand strict transactional guarantees across distributed environments.
Serverless pricing model that scales to zero
Amazon Aurora DSQL benefits include cost-effective serverless pricing that charges only for actual usage. The AWS distributed database architecture automatically pauses during idle periods, reducing costs to zero when applications aren’t actively processing queries, making it perfect for variable workloads.
How Aurora DSQL Handles Data Distribution and Consistency

Automatic data partitioning across multiple regions
Aurora DSQL automatically splits your data across multiple AWS regions using intelligent partitioning algorithms that consider query patterns and access frequency. The system dynamically redistributes data as workloads change, ensuring optimal performance without manual intervention. Each partition maintains metadata about data locality and access patterns, enabling the distributed SQL database to route queries efficiently across regions while maintaining ACID compliance.
Strong consistency guarantees with global clock synchronization
Amazon Aurora DSQL architecture employs a sophisticated global clock mechanism that synchronizes timestamps across all nodes, ensuring strong consistency for distributed transactions. This approach eliminates the common trade-offs found in traditional distributed databases by providing linearizable reads and writes across regions. The system uses hybrid logical clocks combined with GPS-synchronized atomic clocks to maintain precise ordering of operations, guaranteeing that all nodes see transactions in the same sequence regardless of their geographic location.
Conflict resolution strategies for concurrent transactions
The AWS distributed database architecture implements multi-version concurrency control (MVCC) with timestamp ordering to handle conflicting transactions gracefully. When conflicts arise, Aurora DSQL uses deterministic resolution rules based on transaction timestamps and priority levels, automatically retrying failed operations with exponential backoff. Advanced deadlock detection algorithms monitor transaction dependencies across regions, preemptively aborting cycles before they impact system performance.
Cross-region replication and data locality optimization
Data locality optimization in Aurora DSQL intelligently places frequently accessed data closer to application workloads while maintaining synchronous replication for critical consistency requirements. The system analyzes query patterns and user geography to predict optimal data placement, reducing latency for read-heavy operations. Asynchronous replication handles less critical data movement, while hot data remains synchronized across primary regions using quorum-based consensus protocols that balance performance with durability guarantees.
Performance Optimization Strategies for Aurora DSQL Workloads
Query execution planning in distributed environments
Aurora DSQL’s query optimizer automatically analyzes distributed workloads to determine optimal execution paths across multiple compute nodes. The system leverages cost-based optimization that considers network latency, data locality, and resource availability when deciding whether to push computations closer to data or consolidate results at specific nodes. Smart query planning reduces cross-node data movement by identifying opportunities for local filtering, aggregation, and join operations before transmitting results across the distributed infrastructure.
Connection pooling and session management best practices
Effective connection pooling becomes critical for DSQL workload optimization since distributed queries can span multiple database endpoints simultaneously. Configure connection pools with appropriate sizing based on your application’s concurrency patterns, typically maintaining 10-15 connections per CPU core across your compute fleet. Session affinity helps maintain query context and temporary objects, while connection multiplexing reduces the overhead of establishing new database connections for short-lived operations in serverless environments.
Monitoring and troubleshooting distributed query performance
Performance monitoring in Aurora DSQL requires tracking metrics across distributed query execution phases, including parse time, optimization duration, and cross-node data transfer volumes. Use CloudWatch to monitor query latency patterns, connection pool utilization, and resource consumption across compute nodes. When troubleshooting slow queries, examine the distributed execution plan to identify bottlenecks like excessive data shuffling, uneven partition distribution, or suboptimal join strategies that force large dataset movements between nodes.
Migration Pathways and Integration Considerations
Transitioning from traditional relational databases
Moving from conventional databases to Aurora DSQL requires careful planning around schema design and transaction patterns. Legacy applications built for single-node databases often need adjustments to handle distributed SQL’s eventual consistency model and cross-region data placement strategies.
Application code modifications for distributed SQL patterns
Database connection pooling and retry logic become critical when adapting applications for Aurora DSQL’s distributed architecture. Applications must implement proper error handling for network partitions and optimize queries to leverage DSQL’s distributed processing capabilities while maintaining data integrity across multiple availability zones.
AWS service integrations and ecosystem compatibility
Aurora DSQL integrates seamlessly with Lambda functions, API Gateway, and CloudFormation for automated deployments. The service supports standard SQL interfaces, making it compatible with existing BI tools, ETL pipelines, and monitoring solutions while providing native CloudWatch metrics for performance tracking.
Cost analysis and ROI calculations for enterprise adoption
Aurora DSQL’s serverless pricing model eliminates over-provisioning costs compared to traditional database instances. Organizations typically see 30-50% cost reduction through automatic scaling and pay-per-request billing, especially for variable workloads with unpredictable traffic patterns that would otherwise require expensive always-on infrastructure.
Aurora DSQL represents a significant shift in how developers can approach distributed database challenges on AWS. The service’s unique architecture tackles the complex problems of data distribution and consistency while delivering the performance and scalability that modern applications demand. From its intelligent data partitioning to its strong consistency guarantees, Aurora DSQL removes many of the traditional barriers that have made distributed databases difficult to implement and manage.
The migration pathways and optimization strategies we’ve covered show that adopting Aurora DSQL doesn’t have to be an all-or-nothing decision. Teams can start small, test specific workloads, and gradually expand their usage as they become more comfortable with the technology. If you’re dealing with scaling challenges or consistency issues in your current database setup, exploring Aurora DSQL’s capabilities could be the game-changer your applications need. Start by identifying a single use case where distributed SQL could make an impact, and begin your journey toward more resilient and scalable data architecture.
The post Distributed SQL on AWS: Understanding Aurora DSQL Internals first appeared on Business Compass LLC.
from Business Compass LLC https://ift.tt/iDyzal7
via IFTTT



Comments
Post a Comment