Podcast - Guarding Against Phantom Data Loss in PySpark ETL Pipelines: A Group-By Strategy
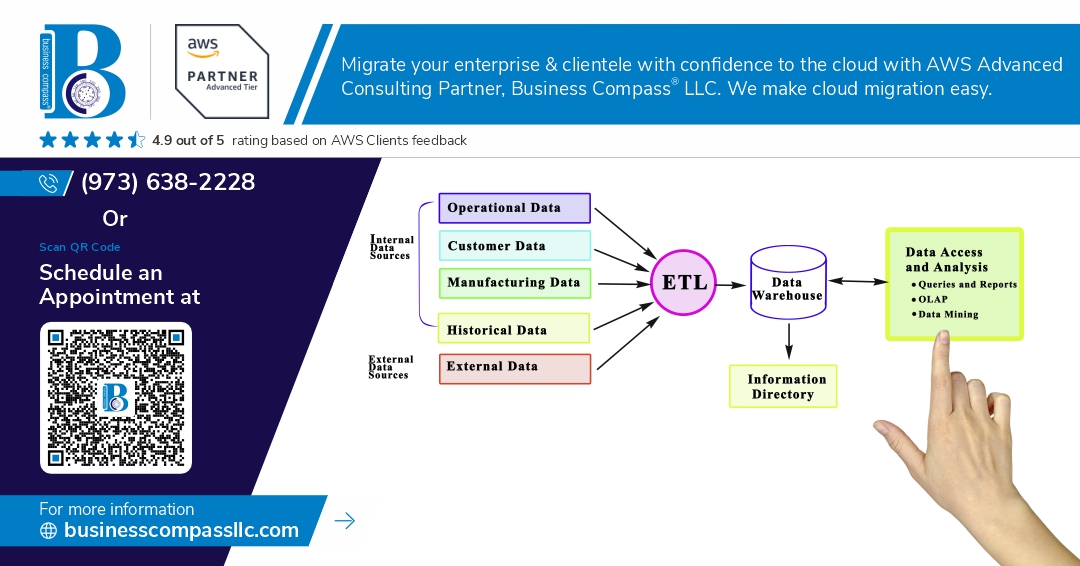
Data engineering is often fraught with challenges, and one of the most insidious issues is phantom data loss, particularly during the ETL (Extract, Transform, Load) process. This podcast explores the nuances of unintentional data loss when using group-by operations in PySpark and provides practical solutions to ensure data integrity and maximize record uniqueness.
#DataEngineering #PySpark #ETL #DataIntegrity #BigData #DataAnalytics #MachineLearning #DataScience



Comments
Post a Comment